Debugging and Profiling Parachain Performance: A Comprehensive Guide
This article provides insights into debugging issues on a parachain and demonstrates how to profile the WASM code to investigate performance problems. The content is based on a report from a parachain team. Let's begin with the reported issue.
The issue
A team was testing their parachain by sending a huge number of batched calls. Each call in these batches was a Balances::transfer_keep_alive. The team was reporting that after sending a certain number of transaction, the transactions seemed to be stuck in a loop. By loop, they meant that the RPC node was reporting that each of these transactions was going from Future to Ready to InBlock and then starting all over again.
The team provided the script that they used to test their parachain. This made it quite easy to reproduce the problem in the end. However, when first testing the script on a local network (two relay chain validators plus two collators of the parachain) the error could not be reproduced. When testing the script against the same parachain being registered on Westend, while having the collators running on some cloud machines, the issue was reproducible. That the issue was reproducible only on cloud machines, but not on a local machine already hinted at some potential performance problems. Nevertheless, the first direction of the investigation was the transaction pool.
Let's check the transaction pool
Based on the explanation of the issue, the first assumption was that the transaction pool was having issues. The transaction pool can be debugged by enabling the txpool (pass -ltxpool=trace to any Substrate-based node) logging target. It is best to enable the logging for the transaction pool on the RPC node that receives the transactions and on the collators. The logs will look similar to this (additionally with basic-authorship=trace logs enabled):
20:45:42 txpool: [Parachain] [0x65cda7e58d6d7d9fc80bf803e97ffc4080896810e6f9d3968131ad8fa8791e71] Importing to ready
20:45:48 basic-authorship: [Parachain] [0x65cda7e58d6d7d9fc80bf803e97ffc4080896810e6f9d3968131ad8fa8791e71] Pushed to the block.
20:45:49 txpool: [Parachain] [0x65cda7e58d6d7d9fc80bf803e97ffc4080896810e6f9d3968131ad8fa8791e71] Pruned at 0xbdb021f05fab7a02d27a28bf8e21a03a8eeff2f802b4fddd4c08483b02527a88
20:46:42 txpool: [Parachain] [0x65cda7e58d6d7d9fc80bf803e97ffc4080896810e6f9d3968131ad8fa8791e71]: Resubmitting from retracted block 0xbdb021f05fab7a02d27a28bf8e21a03a8eeff2f802b4fddd4c08483b02527a88
20:46:42 txpool: [Parachain] [0x65cda7e58d6d7d9fc80bf803e97ffc4080896810e6f9d3968131ad8fa8791e71] Importing to future
-
20:45:42: The transaction0x65cda7e58d6d7d9fc80bf803e97ffc4080896810e6f9d3968131ad8fa8791e71gets included in the transaction pool into thereadypool. The transaction pool differentiates betweenfutureandreadytransactions. Each transaction canprovideandrequireso-calledtagsin Substrate. Such atagis for example thenonceof a transaction. When all therequiretags of a transaction are fulfilled, it is put into thereadypool. -
20:45:48: The transaction is put into the block0xbdb021f05fab7a02d27a28bf8e21a03a8eeff2f802b4fddd4c08483b02527a88(the hash of the block that was built is not shown here directly). -
20:46:42: For almost one minute the transaction did not appear again in the logs, but then it gets added back to the transaction pool into thefuturepool, because the block0xbdb021f05fab7a02d27a28bf8e21a03a8eeff2f802b4fddd4c08483b02527a88was retracted. A block is retracted when it was thebestblock or part of thebestchain before, but then there appeared another chain of blocks appears that is "better" (longer, included in the relay chain or whatever fork choice rule is being used).
This is basically the behavior the team was reporting. The transaction was switching between different states over and over again (the logs shown above were basically repeating all the time). The same was happening to multiple transactions.
Why are the transactions jumping between states?
As of writing this article, it was known that the transaction pool is buggy when it is coming to parachain block production. The root cause of the transaction pool issue is that the parachain block production is triggered by each relay chain block. The block production logic determines if the local collator is eligible to build a block and then depending on the check builds a block. If multiple relay chain validators for example build multiple blocks on the same height (these are called forks and can happen with BABE), the parachain block producer will also build the same amount of forks. The important difference here is that for the parachain one collator is building all the forks, while for the relay chain multiple validators build the forks. This triggers the bug in the transaction pool implementation. The image below should illustrate the issue:
Each of the relay chain blocks X and X' triggers the parachain block production. This happens sequentially, this means that first X triggers the parachain block production of Y, Y is finished and then X' triggers the parachain block production of Y'. The parachain block production is communicating with the transaction pool to fetch the transactions that should get included in the block. After Y is build, the transaction pool is informed about this block and the transaction it includes. The transaction pool will prune the transactions from its state as they got included in a block. The problem arises now from the fact that X' triggers the block production of Y', a block on the same height as Y. Actually the transaction pool should return the same transactions as for Y, but it already pruned them and thus, returns no transactions at all. If the transaction pool contains transactions from the same sender (with increasing nonces) and some of these transactions get included in Y, the transaction pool will may return transactions from the sender to be included in Y'. The problem there is that the transaction for Y' will have a too high nonce and thus, will be rejected as invalid by the runtime. So, the collator is reporting valid transactions as invalid, because the transaction pool returned transactions for Y' that should not yet get included.
In the case of the issue that is analyzed in this article, one collator was always building one block with the same number transactions in it. As described above, these transactions got removed from the transaction pool, because they are included in a block. Both collators continued to produce blocks without these transactions included until the block with the transactions got retracted, because it was part of a fork that is not the best chain anymore. After the block got retracted, the transactions got re-added to the transaction pool and could get included in a new block. This behavior was continuing over and over again, leading to these observations of the transactions jumping between the Future, Ready and InBlock state. Somehow the block that included the transactions never made it into the canonical chain. After some time the entire parachain stalled. The collators were still producing blocks, but always on the same height. This indicated some issue with the PoV (proof of validity) validation of the parachain on the relay chain validators.
Why did the parachain stall?
When looking at the Westend relay chain logs, they revealed the following:
parachain::candidate-backing: Validation yielded an invalid candidate candidate_hash=0xf757dbcf67242fe613438793ffbaf27d9f65efc898986645e917a86256cdb599reason=Timeout traceID=328775503065420294315931826116861031037
The important piece of information here is the reason=Timeout. This means that the validator did not manage to validate the candidate on time. When it comes to the PoV validation, the Polkadot validators currently use the CPU time to measure execution time to ensure that the execution stays within the expected limits. However, by using the CPU time it is quite important that the validators are using at least the reference hardware to ensure that they can validate the PoV in time. When the validation fails to finish on time, it could, for example, mean that the parachain is malicious or maybe the weights of the parachain are not benchmarked correctly. Let's take a look at the collators and how long they took to produce a block:
sc_basic_authorship::basic_authorship: [Parachain] 🎁 Prepared block for proposing at 6615 (1152 ms) [hash: 0x1275e2d5cfcb49cdf944b43f59043fccd151931a31335b918fc43f4395788ab1; parent_hash: 0xc5bb…4941; extrinsics (18): [0x59de…0071, 0x1f0d…6c3a, 0x264c…2b9b, 0xc262…4d25, 0xb130…0cae, 0x38a3…05a3, 0x0eef…a86b, 0x7199…180d, 0xba89…5348, 0x7ba4…c39a, 0x74be…869d, 0x8995…839a, 0x6e5d…fcf8, 0xe31c…019b, 0xeb87…24f1, 0x8ea7…8358, 0xdc20…ae3a, 0x17e9…9ed7]
The collator managed to produce the block in 1152ms, which is well below the validation execution limit of 2000ms. The collators and the Westend validators also used the same hardware configuration. Thus, they should be able to validate the PoV in the same amount of time or even faster, because validation is running entirely in memory and does not require reading data from disk. So, one of the only explanations left was that the validation was actually slower than the block production.
To verify this assumption, it is necessary to re-run the verification of the PoV in a more controlled environment that allows attaching a profiler. With this pull request the collator can be instructed to export all the built PoVs to the filesystem. The cumulus-pov-validator tool introduced in the same pull request can be used to validate these PoVs in isolation. First, the polkadot-parachain based collator needs to be instructed to export the PoVs:
polkadot-parachains --collator --chain CHAIN --export-pov-to-path SOME_PATH
The collator will export all the PoVs it is building to the given path SOME_PATH using the naming scheme BLOCKHASH_BLOCKNUMBER.pov. After capturing some problematic PoVs, they can be validated using:
cumulus-pov-validator --validation-code PATH_TO_CODE_OF_THE_PARACHAIN --pov PATH_TO_ONE_OF_THE_EXPORTED_POVS.pov
The validation code is the parachain runtime that is registered on the relay chain. However, it is not required that the validation code used for the "local" validation be the same as registered on the relay chain. This opens the possibility to change the code as required to, e.g., add more debugging output or to optimize certain code paths.
To have the best comparison between building and locally validating the PoVs, it is best to run both on the same machine to get comparable results. When building the same problematic PoV on a local machine, it took 748ms:
[Parachain] 🎁 Prepared block for proposing at 1737 (748 ms) [hash: 0x156cac27caf880b8711ae0892ea2d1bac761c143c883008a36e350b9d536c681;
When validating the same PoV on the same machine, it took 1724ms:
cumulus_pov_validator: Validation took 1724ms
So, the validation took more than twice as long as the block production on the local machine, which is more powerful than the cloud machine running the collators/validators. On the cloud machine, it took 1152ms to build the PoV and when put into correlation with the results of running the validation on the local machine, the validation on the validators took more than 2s. The assumption that validation took more than 2s is backed by the observed Timeout error on the validators. Based on these results, it is obvious that the validation timeout is related to the actual validation code and not to some performance issue in the Polkadot node.
Why is the validation more than twice as slow?
Let's start with a brief introduction on how parachain validation works. Each parachain registers the so-called validation code as a WASM blob on the relay chain. This WASM blob needs to export a function called validate_block. The input to this function is the PoV, the previous head of the parachain, the block number, and the storage root of the relay chain block that was used when building the PoV. The PoV contains the storage proof with all the storage entries required for executing the block, the relay chain validator doesn't have any access to the state of the parachain.
Accessing the state from inside a parachain runtime is done using a host function. When building a PoV, these host functions call into the parachain node that has access to the state of the parachain. As explained above, while validating a block, the required storage entries from the state are part of the PoV itself, and the host executing the validation is a stateless process from the relay chain.
To enable the validation to access the parachain state, the host functions used to access the state are redirected. Thus, these host functions do not call into the host process but stay inside the WASM execution context of the validation code. The state data required by the host functions when executing the validation is fetched from the storage proof that is part of the PoV.
To get some insights into the validation and where the execution is spending its time, a profiler is the best tool. By leveraging the cumulus-pov-validator, the profiler will only profile the actual execution of the validation, with the only noise being the compilation of WASM to native bytecode. wasmtime (the WASM compiler used by Substrate) provides a guide on profiling, and on Linux, the supported profiler is perf. The actual command line to profile cumulus-pov-validator looks like this:
WASMTIME_PROFILING_STRATEGY=jitdump\
perf record -g -k mono cumulus-pov-validator --validation-code\ PATH_TO_CODE_OF_THE_PARACHAIN --pov PATH_TO_ONE_OF_THE_EXPORTED_POVS.pov
The environment variable WASMTIME_PROFILING_STRATEGY instructs the Substrate wasmtime executor to enable the jitdump profiling strategy. After the execution is finished and the profiler has stopped, the *.dump files need to be merged into perf.data:
perf inject --jit --input perf.data --output perf.jit.data
Then the data from the profiler is ready to be inspected:
perf report --input perf.jit.data
The output of the command will look like this:
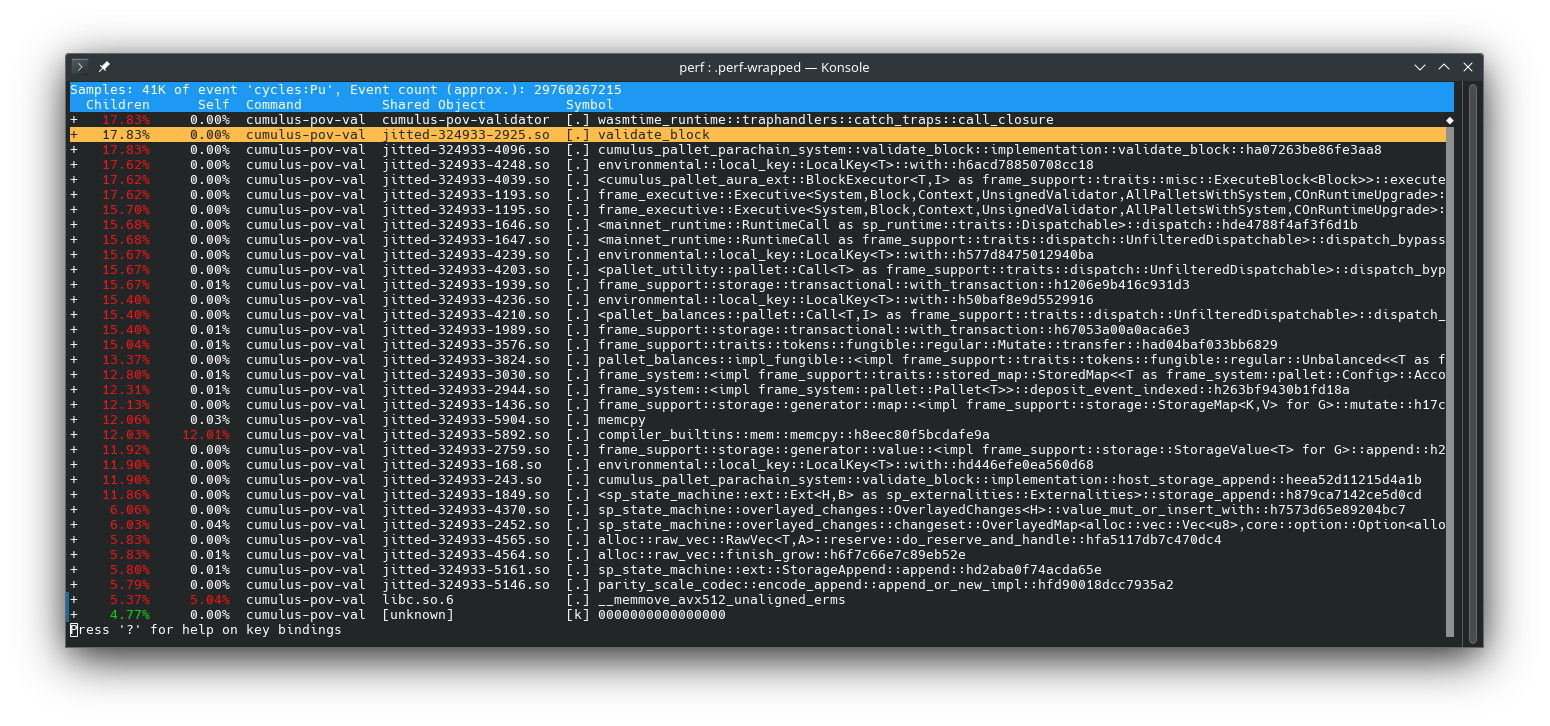
The list is ordered by the percentage of the total amount of time spent in each function (first column), including the children called by this function. The second column is the percentage of the total amount of time spent in the function itself. There we see that memcpy is taking 12% of the total execution time of the validation. The entire validation is done inside the validate_block function that is provided by the validation code. To find out where the execution time was spent in this function, the call graph can be expanded like this:
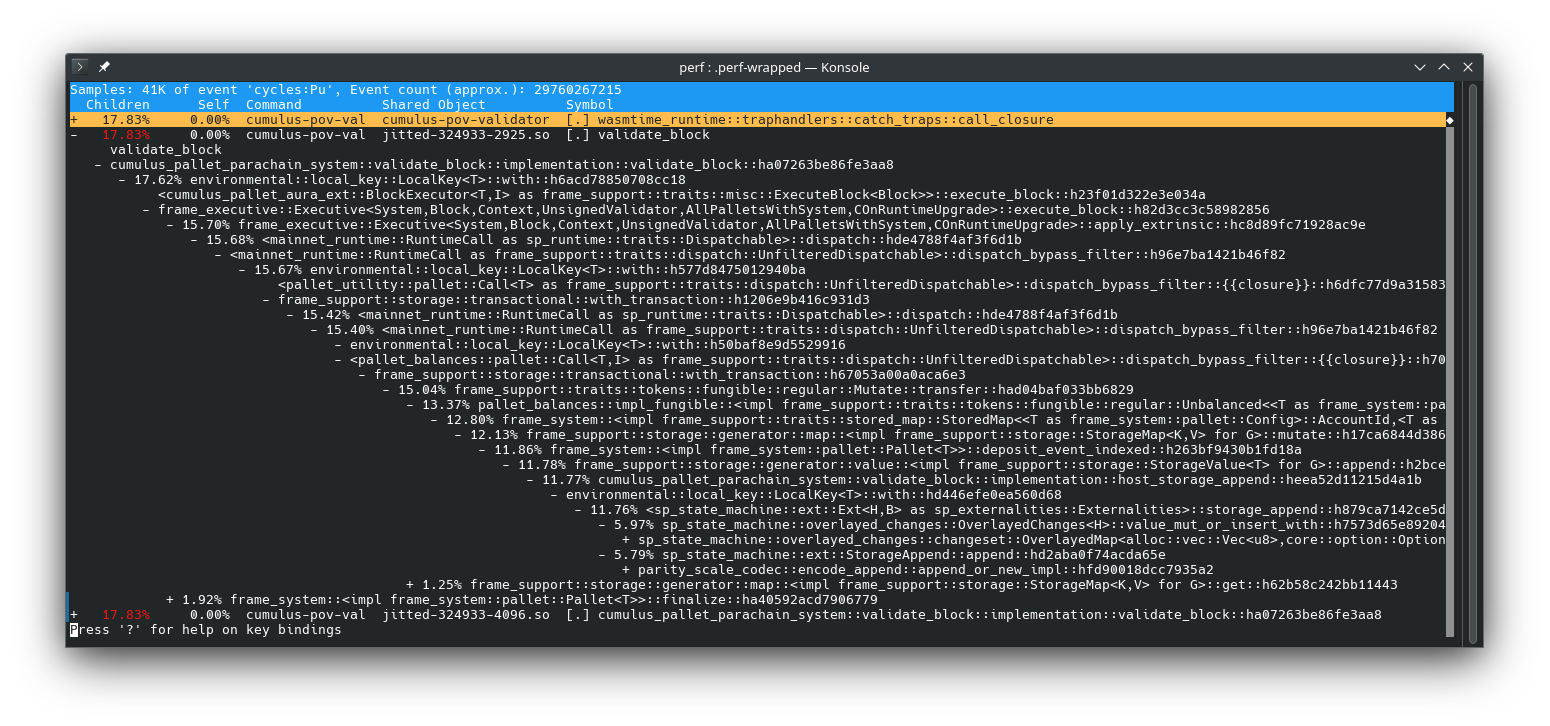
This shows that 11.77% of the total time is spent in append_storage, which is called by deposit_event. deposit_event is used by pallets to inform external applications about important operations that have happened in a block. Depositing events should be an operation that is almost transparent and doesn't take much time to execute. Luckily, at the time of detecting the issue, there was already a pull request available to fix the underlying issue. The assumption was that the combination of batches, where each batch is creating its own storage transaction together with deposit_event, led to a lot of allocations. A storage transaction creates a transaction-like access to the storage, which means that at the end of the transaction, all writes can be discarded or applied to the underlying transaction (there is always the "base" transaction that will ultimately be applied to the backend). deposit_event itself was not creating all these allocations, but it was storage_append. storage_append is a host function for appending to some storage entry in an effective way that doesn't require decoding the entire storage value. When executing the validation code, storage_append is running inside the WASM execution. However, each allocation is a host function call, which slows down the execution. When a lot of allocations are happening, this can have a severe impact on the execution time. In contrast, when building the block storage_append is executed by the node and the allocations are handled on the native side, not requiring the "context switch" from WASM to native. To confirm the assumption, the validation code was rebuild with the pull request applied and thePoV was re-executed with the fixed validation code. The run with the fixed validation code was slightly faster 688ms than the block building 748ms, thus the performance issue is fixed and the assumption that the number of allocations killed the performance was correct.
Recap
Everything began with a report of a parachain team that was seeing transaction statuses fluctuating between Future, Ready, and InBlock. Eventually, the parachain completely stalled on the relay chain, while the collators continued to produce blocks, albeit the same ones repeatedly. The relay chain was not accepting the collations. Logs from the Westend validators revealed that the collation validation was timing out. Collation validation was taking twice as long as the block production. After some investigation deposit_event was identified as the culprit, because its internal usage of storage_append, combined with storage transactions, led to numerous allocations. The performance issues with the collation validation were a result of the numerous allocations.
This article explains how these issues were approached and solved. It provides insights into the internals of Substrate, introduces the cumulus-pov-validator and offers guidance on using perf as a profiler for a Substrate-based WASM runtimes.