From 12s to 500ms - The long road to faster blocks

When parachains launched in 2021 on Polkadot, they were running with a block interval of 12s. The block interval is the time between individual blocks. Each of these blocks was allowed to use 500ms of execution time. These restrictions were lifted with the switch to Asynchronous Backing on Polkadot.
With Asynchronous Backing, parachains were able to build blocks every 6s and use up to 2s of execution time per block. But 6s is not the end for block times, and parachains can actually go much lower than this. While Asynchronous Backing was a relay chain feature, it also enabled feature development on the parachain side to reduce the block times even further. Over the last year, this feature was referred to as "500ms blocks" or "BastiBlocks™," while Block Bundling (thanks to Sebastian for this name) is actually the more correct naming.
Together with Elastic Scaling (another feature on the relay chain), PoV Bundling allows parachains to choose almost any kind of block interval (there are some physical restrictions) while running on multiple cores on Polkadot in parallel. In this article, I want to explain why Polkadot launched with a forced 12s block interval for parachains and how Asynchronous Backing improved this to 6s. Then I want to explain how Block Bundling works. Lastly, I want to answer the most burning question, "Wen?!?" and take a small outlook into the future.
12s block times with Parachains Protocol V1
The parachains protocol launched as version V1 on Polkadot in 2021 and allowed parachains to produce blocks every 12s. A funny side note: when developing the early versions of Cumulus, parachains were able to produce blocks every 6s. At this time, it was using version V0 of the parachains protocol. Sadly, it was not really scaling that well and was full of security issues. So, with V1 a more secure and better scalable version was developed, which is still the foundation of what is running in production nowadays.
To understand why parachains were only allowed to produce blocks every 12s, we need to understand how the parachains protocol is verifying state transitions of parachains. Polkadot can actually not really verify that a state transition of a parachain is valid, because it has no idea about the state transition function used by a parachain. To solve this, Polkadot requires that parachains provide the so-called validation code. This validation code is some WASM code blob that is required to export a function called validate_block. This function takes the previous state commitment of the parachain and the Proof of Validity (PoV), and then it is the job of the validate_block implementation to ensure that the presented state transition is correct.
The parachain collators are building PoVs and sending them to a dedicated group of Polkadot validators (backing group) that are assigned to verify the state transitions of a specific parachain. These validators are rotating in specific intervals. When the majority of this validator group backs a candidate, this candidate can go on-chain. On-chain, this candidate is then starting in the backed state. All relay chain validators will learn about this candidate when they import the relay chain block that put this candidate into the backed state. As the candidate that is stored on-chain is only a commitment to the real candidate, the relay chain validators will start fetching Erasure Encoded pieces from the backing group validators. This is done to make the candidate available in the Data Availability layer of Polkadot. Each validator that received its dedicated piece signs a message saying "I have my piece for X" (not really implemented this way, just here for illustration purposes) and gossips this message plus a signature with all the other validators. The next block author pushes these messages on-chain. When 2/3+1 validators have announced that they have their piece of a parachain candidate in the backed state, the candidate is treated as available and goes on-chain into the included state.
After a candidate has moved into the included state, the candidate is in the last phase, the approval phase. In the approval phase, a group of randomly selected validators fetch the full candidate and validate it again. If one of them disagrees with the validity of a candidate, it may raise a dispute which may lead to the entire validator set checking a candidate for its validity. In the more common case of not finding any problems, the candidate is approved. After all candidates of one relay chain block are approved, the relay chain block is allowed to be finalized by Grandpa.
So, each parachain candidate needs to go through three phases: Backing, Availability and Approval.
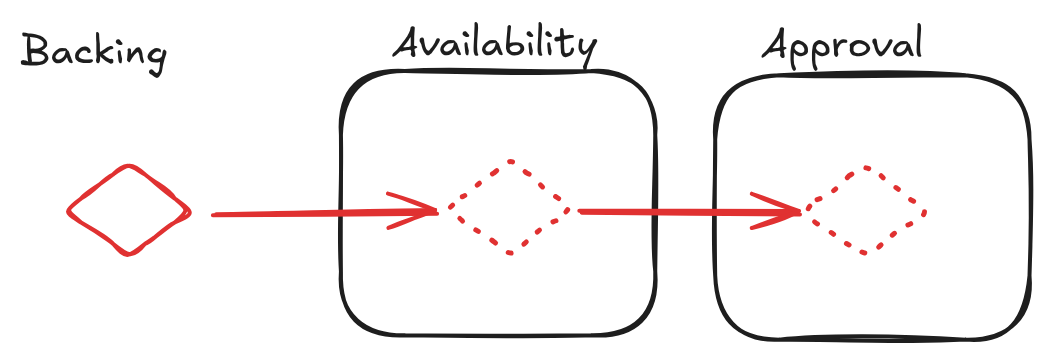
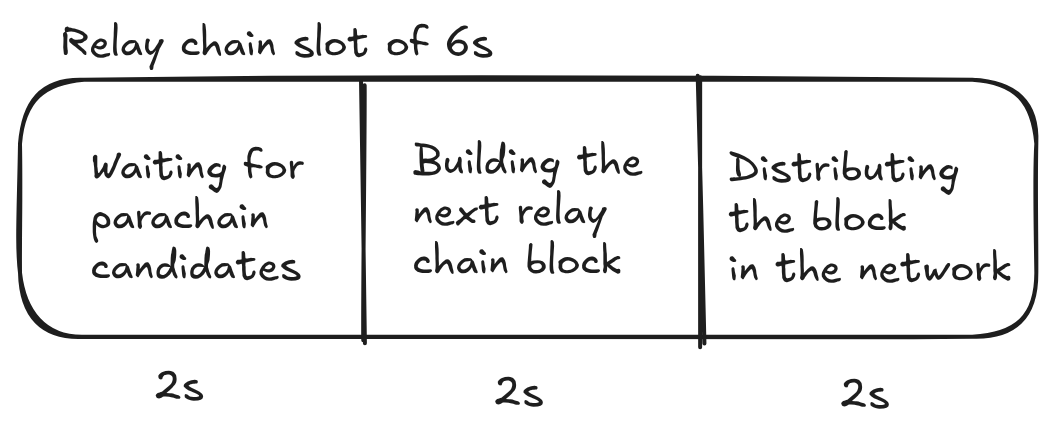
While a parachain candidate is in the backed state on chain and waiting for the availability of its PoV, no other parachain candidate can be backed. Between a candidate getting backed on chain and being included on chain it takes at least two relay chain blocks. In the first block the parachain candidate gets backed, then the validators fetch their pieces, report the availability, and then the candidate gets included in the next relay chain block. The approval process, being completely off-chain, does not delay the parachain block production. The relay chain also requires that any parachain candidate getting backed is built on top of the same relay chain block as the relay chain block that will back the parachain candidate. So, let's assume we are at relay chain block X. The parachain builds a block referencing relay chain block X, sending the PoV to the relevant validators, and they are required to validate the PoV in time. For this entire process, they have around 2s, because then the next block author would start producing their block X + 1. For reference, the relay chain slot partitioning:
The block X + 1 would be built on top of the state of X. If the parachain candidate would not reference X as well, it would not be accepted by X + 1 as a valid candidate. At X + 2 the parachain candidate is then hopefully available and can be included on-chain. The parachain collators could then start producing a PoV on top of X + 2, and the entire process would start again. When observed over multiple parachain candidates, it would look like this:
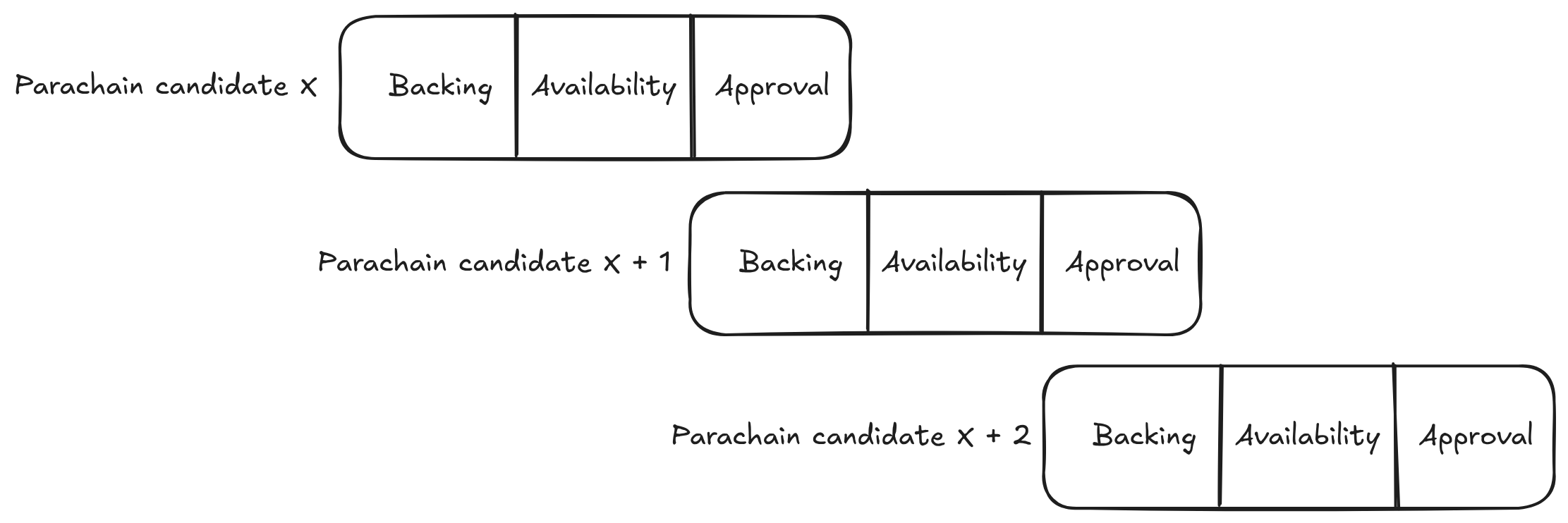
So to recap:
- Parachain candidates need to get backed and included on the chain, which takes at least two relay chain blocks.
- The relay chain has a block interval of
6s, which means that two relay chain blocks will take12s, which explains why parachains could have a block interval of at least12s. - A parachain candidate was required to be built on top of the same relay chain block as is being used to build the next relay chain block to be backed on the chain.
- Approval was always an asynchronous step that did not delay parachain block production.
Asynchronous Backing
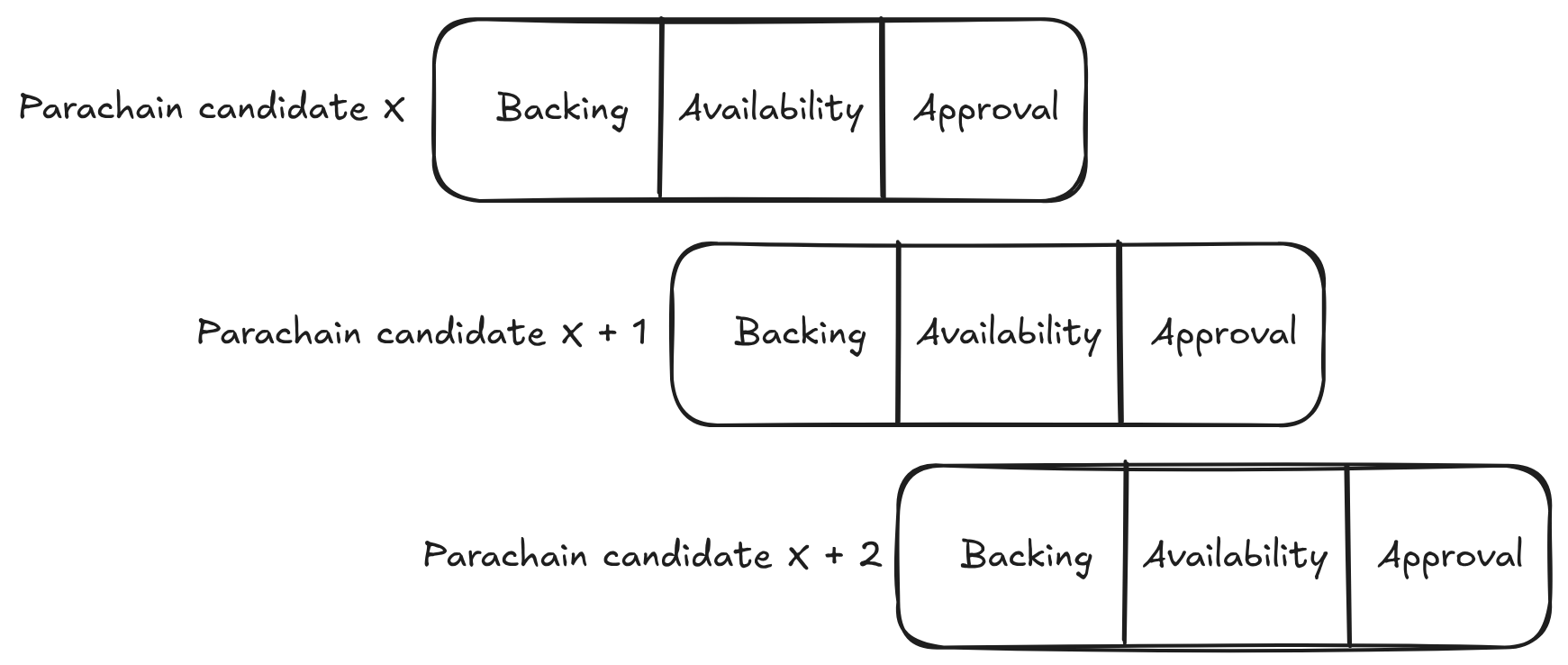
Asynchronous Backing, as the name already suggests, makes the backing phase asynchronous as well. So, instead of needing to wait for a parachain candidate to be available and included on-chain, relay chain validators accept a new parachain candidate for backing while the previous parachain candidate is still being made available. When observed over multiple parachain candidates, the parachain consensus is pipelining the processing of candidates:
Besides pipelining the processing of candidates, asynchronous backing also brought another important change, the allowance of older relay parents as context for the parachain candidates. V1 of the parachain consensus required that the parachain candidates backed on the chain in the relay chain block X + 1 were built in the context of the relay chain block X:
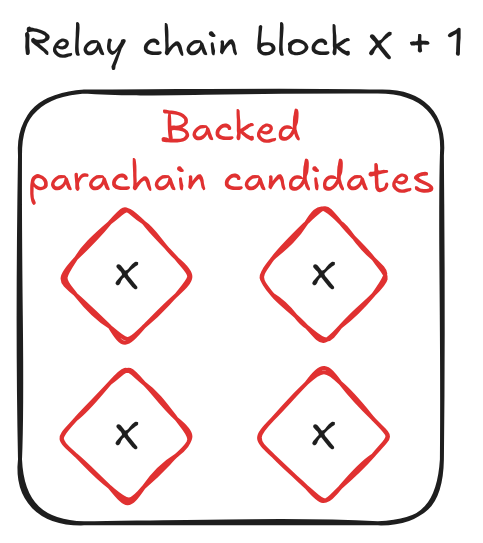
With asynchronous backing and allowing older relay parents, a relay block may look like this:
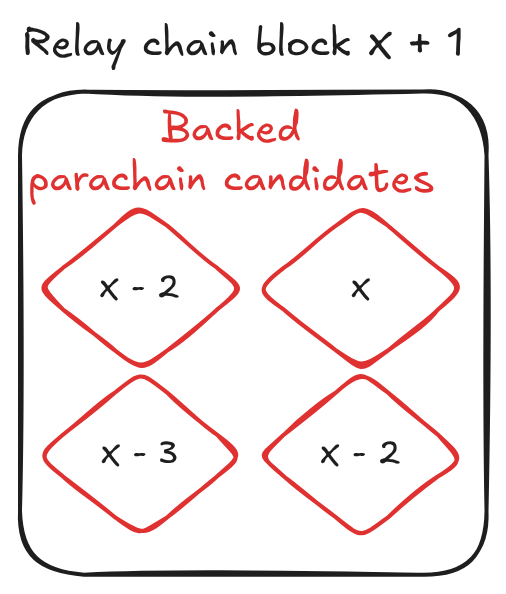
To allow older relay parents, the relay chain runtime needs to store some information about each relay parent in its state to validate parachain candidates. However, the relay chain cannot keep the information about all the previous relay parents in its state, because this would result in unbounded state growth and also the complexity for validating parachain candidates would increase.
Both of these changes together allow parachains to build blocks every 6s. Similar to the relay chain validators, the parachain collators start building blocks on the parachain candidates which are not yet included on the relay chain and are still waiting for their availability. If a candidate never becomes available, it means that the chain of blocks built on top of this candidate will get invalidated and need to be created again, ultimately resulting in some reorganization of the chain on the parachain side. The allowance to reference older relay parents in parachain candidates makes the parachain block production more independent of the relay chain. V1 required using the latest relay chain block as a reference, while Asynchronous Backing allows a window of relay chain blocks as reference.
So to recap:
- Relay chain validators accept parachain candidates for backing while the parent of the candidate is still waiting for availability.
- Collators are building blocks on candidates which are still waiting for availability, so they can build blocks every
6s. - Allowing older relay parents as a reference for parachain candidates decouples parachain block production from the relay chain to some degree.
Elastic Scaling
Elastic Scaling allows a parachain to use multiple cores at the same point in time. So far, parachains were only able to occupy one core at a time. This meant they had 2s of execution time and 5MiB (10MiB in production right now) of storage size available for every PoV.
The basic idea of Elastic Scaling is that when parachains need more of these resources, because they have, for example, a spike in usage, they can use multiple cores to work through this spike. Later on, they would scale down to one core.
From an architectural point of view, the implementation of Elastic Scaling only required changing the assignment of backing groups from parachain ids to core ids. So, before, one backing group was assigned to a specific parachain, identified by some unique identifier (the parachain id). With Elastic Scaling, each backing group is assigned to a specific core id. That's it, an extremely simple change :)
With 3 cores assigned to one parachain, it could produce blocks every 2s, every block occupying one full core. Theoretically, there would be no limit, and one parachain could occupy all cores, enabling the parachain to produce blocks every 6s / 100 = 60ms (assuming 100 cores on the relay chain). But decreasing the block interval of parachains by increasing the number of allocated cores would lead to a huge waste of resources, because each PoV would be far away from the upper limits of 2s and 5MiB per core. To prevent wasting resources on the relay chain side, it requires changes to the parachain architecture, and this is what we call Block Bundling.
Block Bundling
So far, the parachain block production has been depending on the throughput offered by the relay chain itself. Starting from a block every 12s down to theoretically a block every 60ms when using 100 cores of the relay chain. However, these theoretical 60ms would waste 100 * 2s - 6s = 194s of execution time (assuming the parachain manages to use 6s of execution time) on the relay chain and also a lot of data availability bandwidth because these 100 PoVs are not filled to the max. Because the parachain would occupy 100 cores, there would be no cores left to process other parachains (assuming the relay chain provides 100 cores). Given these constraints, no one would run a parachain with this configuration in production.
With Block Bundling, the parachain block interval is separated from the available resources on the relay chain. So, instead of building X blocks for X cores, the parachain will build blocks in the configured block interval while ensuring that blocks will fit into the available resources provided by the relay chain cores.
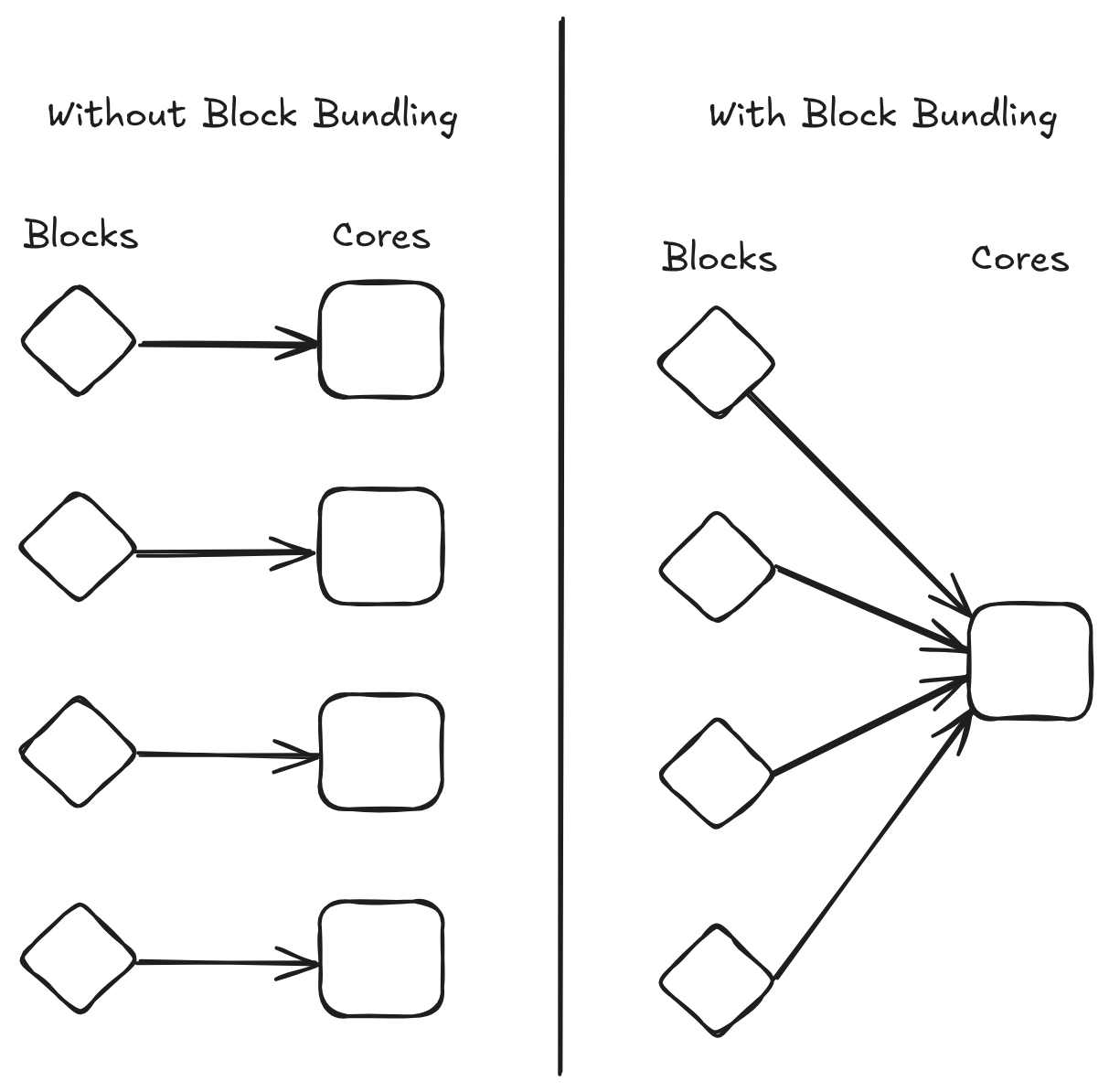
The name Block Bundling is self-explanatory by the fact that you take multiple parachain blocks and bundle them into one PoV. It will not only support bundling multiple blocks into one PoV, but actually into multiple PoVs to make use of all allocated cores.
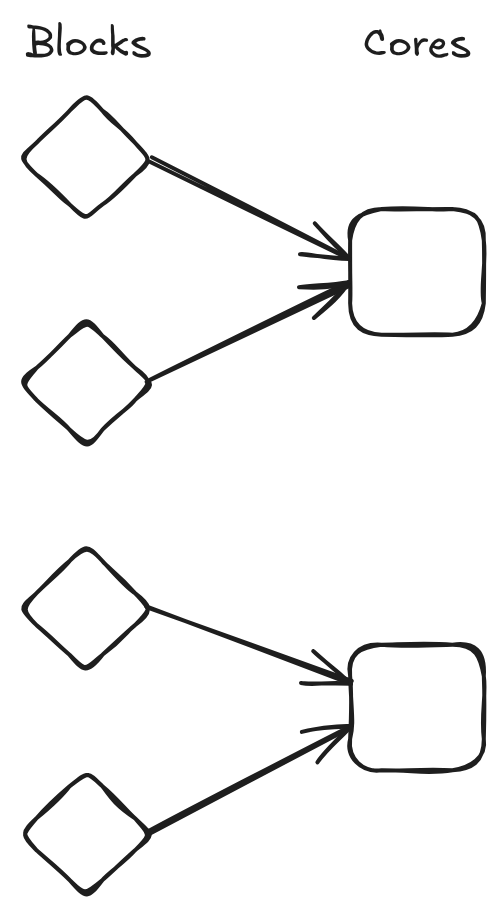
The block production logic will fetch the available cores from the relay chain and calculate how many blocks to put onto each core. Each block will ensure that it only uses its fraction of the core, so that all blocks together don't overshoot the resource limit of a core.
Minimum Block Interval
To interact with a blockchain, users are sending transactions. These transactions are getting included in blocks and when a transaction is included in a block a user gets feedback for their transaction. So, blockchains are trying to lower their block interval as much as possible, because this reduces latency for users. There are also other ways to reduce latency for users like e.g. preconfirmations. In the context of blockchains it is not only about reducing latency, but also certainty that a transaction is included and the result of the transaction, e.g. did the user buy the rare NFT and not someone else.
The block interval cannot be reduced indefinitely, because the time between two blocks inherently includes the time to produce one block. The time to produce a block depends on the time to run the inherent logic of a block plus the time it takes to execute the transactions of a block. Depending on the parachain logic the time for the inherent block logic is around 5-10ms. A transfer takes around 0.25ms to execute. So, for a block that is allowed to execute for 500ms, it should theoretically fit ~1960 transactions.
There are also other factors to take into consideration, like the size of the collator set and how far (physically) these collators are distributed from each other. Building blocks faster than what it takes for the other side to receive them is not that useful, because it will not improve the latency of the user.
Block Bundling will require that the block author is allowed to change at maximum every 6s (the relay chain block interval). So, there is at maximum one handover to the next block author every 6s. Each handover costs time in which no block can be built. This time is the latency of the next author to receive the latest block and the time of the next author to import the latest block.
The block interval needs to be chosen wisely and depends on the application running on top of the parachain. Setting it to some minimum value that may only allow each block to include one transaction, will make blocks being dominated by their inherent block logic time. Choosing a block interval that is too far above the human input lag (time between seeing and reacting to some signal) of ~273ms, will make the user feel the latency. Other applications may not require low latency at all and produce blocks only on demand.
Dynamically increasing the Block Interval
Block Bundling separates the block interval from the available resources to deliver, e.g. lower latency without wasting the available resources. While this strategy works for most of the use cases, certain use cases may require more resources than what one block is able to provide. One of these use cases is, for example, the ability to upgrade a parachain to a new runtime version. The current default limit for the maximum size of a parachain runtime on the relay chain is 5MiB. As the runtime is upgraded by sending a transaction to the parachain runtime, it means these 5MiB will need to fit into a block. So, the new runtime alone would already use half of the available PoV storage. If a parachain bundles more than one block into a PoV, the parachain could run into issues when trying to upgrade its runtime because such a block would not fit into the limits. To solve this issue, Block Bundling will support the ability to dynamically increase the block interval. Basically, running with a higher block interval for one block to allow the inclusion of one or more transactions that would require more than the normally available block resources. Block Bundling will always allow the first block of a PoV to use the full PoV. To enable full PoV usage, either the inherent block logic or one of the first X transactions of a block will be required to consume more than the available block resources. If one of the conditions is fulfilled, the runtime will set a special signal in the parachain header, informing the node that this block should use the full PoV on its own. Afterwards, the block production will continue as before with the same configured block interval and block resources. While the feature of dynamically increasing the block interval is required to ensure that parachains will always be able to upgrade their runtime or to process other important operational operations, it may also be useful to expose the feature to "normal" users, e.g. to allow chaining of multiple complex smart contracts. It will be up to parachain builders to decide which transactions will be able to opt-in to this feature and thus, using a full PoV.
Wen?!?

Over the last year, I have heard the question of "wen" very often. First, it taught me to not publish information on things I'm working on, without having a clear idea of what exactly the steps are required to accomplish my goal. While I had a working prototype last year, it was hacked together in 3 days ignoring any edge cases. Converting these 3 days of work into an implementation that takes all these edge cases into account, while also being pulled into one million other things (thanks again to the Coretime Baron ❤️), took a little bit longer than expected. Estimations are not my strength and will probably never be :)
However, now I can announce that Block Bundling is feature complete. There are still some optimizations left, but none of them prevent an MVP that can be rolled out to production. The feature is fully implemented with tests in a branch and I have already started to port the changes step by step to master to make the final pull request smaller and better reviewable. To follow the progress more closely, subscribe to this GitHub issue.
Assuming that I will not hit any unforeseen blocker and I can get people to review my changes in time, the feature should be fully merged into master with documentation on how to use it by the end of the year. A first parachain on Westend should then follow very closely, which will produce blocks every 500ms.
Future Outlook
With Block Bundling being feature complete and nearing a state of having an MVP running in production, it doesn't mean that all the development is finished. While the MVP already contains a lot of optimizations to ensure that the performance isn't degrading by building faster blocks, there is still room for improvement.
FRAME pallets are called when initializing and finalizing the creation of a block. Pallets use these opportunities to execute certain workloads. The problem is that most of these pallets were written with the assumption that blocks are being built every 6s. Executing a workload every 6s is clearly something different than executing the same workload every 500ms. So, some pallets could be optimized to only execute their internal workload every X blocks and thus, allowing more transactions to fit into a block.
Right now there is a downtime of one block when rotating authors with Block Bundling. Because authors are first building blocks and then sending them out to the network, it will take other nodes time to download plus import time before they have a block ready. The output state of a block is required to build a new block on top. This explains why there is a downtime of one block when rotating the authors. In the future this should be solved by transaction streaming. A feature that is developed right now and which allows all nodes in the network to build blocks "together". So, the downtime should go down to the latency between the individual authors.